"peripatetic: 7; ludic: 5; corollary: 8"
peripatetic: 7; ludic: 5; corollary: 8
wordscraping
Apr 30, 2025
4
I’ve been maintaining a list of all the new words I encounter for the past five years.
The issue is that I don’t remember all the words perfectly, so I’m sure there are some duplicates. But the document is over 100 pages long.
I’d like to track/clean/count/remove duplicates. It was surprisingly easy to write a script for this!
When I first conceived of this script, I supposed I’d have to implement some convoluted logic—appending words to a list, cross-checking whether each new word is already on the list, and only appending it if that’s not the case.
But there’s actually a far simpler way! Sets don’t include duplicates, whereas lists do. So I was able to just create a set() and let that take care of collecting unique words.
27% of my words were duplicates. The most common:
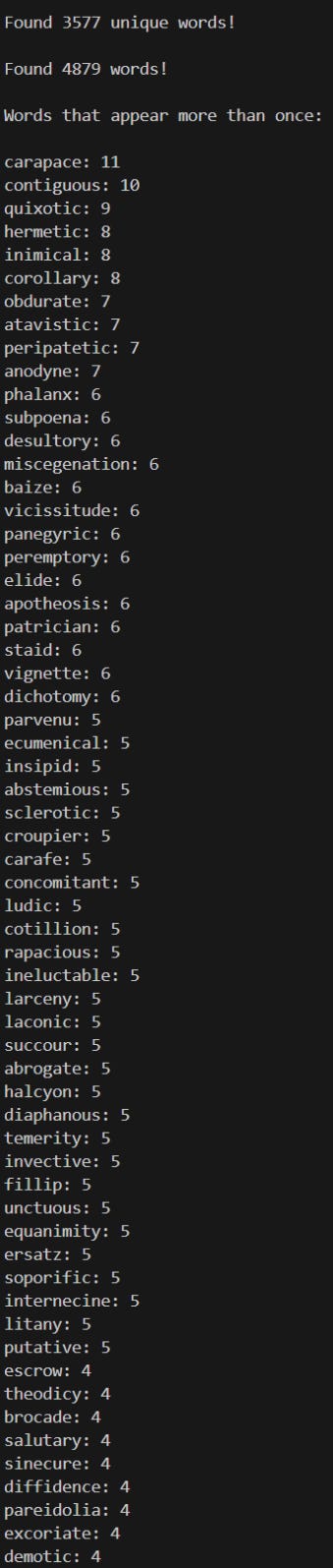
These are the words I encountered most frequently and initially struggled to retain. Some of them seem funny now—they include words I use ~frequently (corollary, vignette, litany) and some of my favorite words (dichotomy, ludic, peripatetic)!
I always had the sense that Python was supposed to be an everyday/scripting language, but I’ve been underexploiting that modality. It’s pretty cool! I’m pleasantly surprised Google’s APIs are so easy to use, as well.
I hope to write more scripts and share them here.
4
Originally published on Substack