"GPT-5 Livestream Notes"
GPT-5 Livestream Notes
Low-tech language acquisition
Aug 08, 2025
7
In the morning, I moved some money from my checking account into stocks, just in case this turned out to be big.
My expectations were deflated by the emphasis on traditional, low-tech language acquisition. Musk’s micro-school, Ad Astra, has skipped teaching foreign languages since ~2014 in anticipation of immediate, real-time computer-aided translation.
Here in 2025, Yann Dubois vibecodes an app to help his partner learn French. This ‘sent me’; the theme is evergreen.
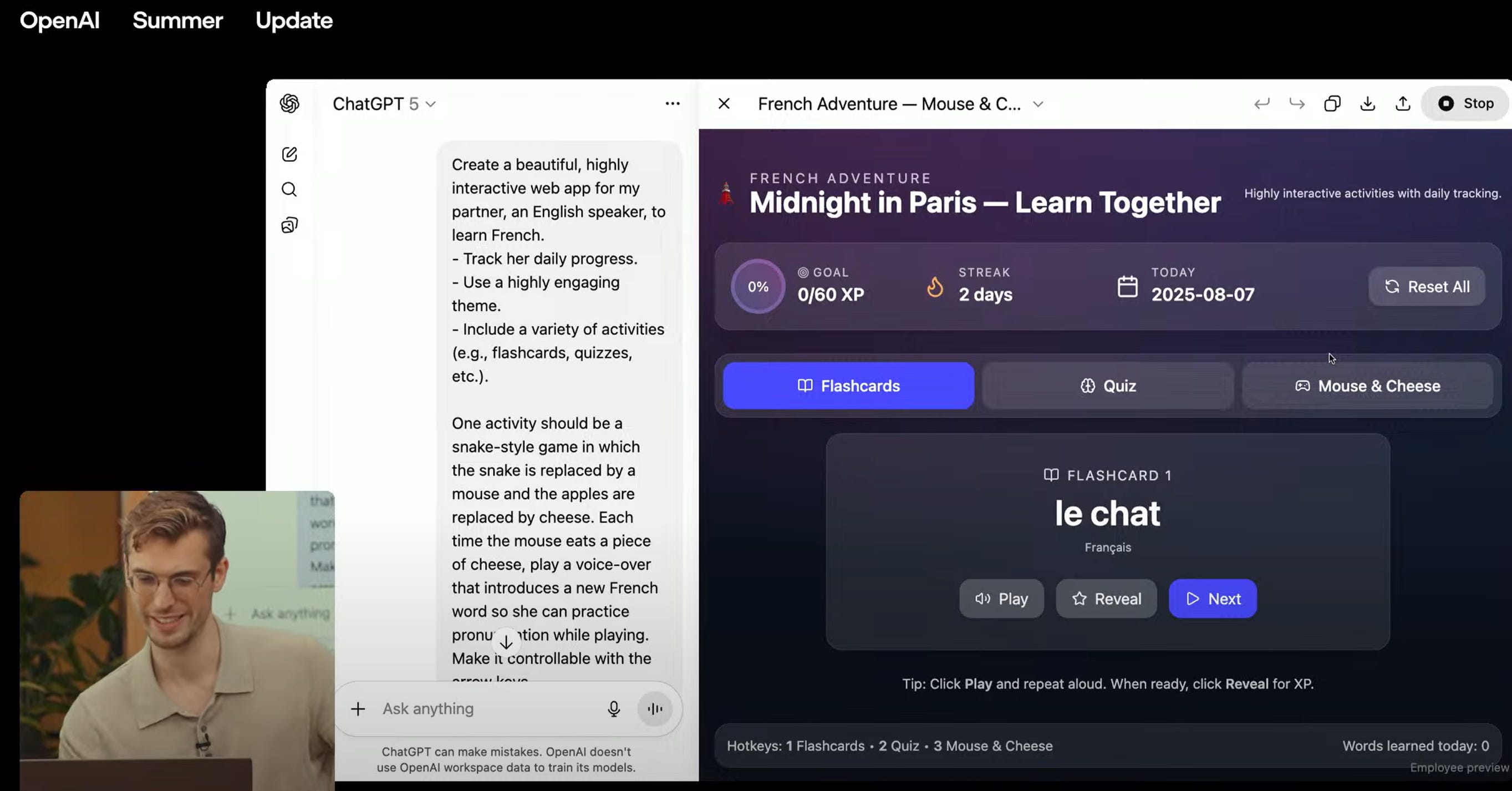
Where’s the spaced repetition? OK, I appreciate this as a vehicle to show off GPT-5’s webdev. But it’s not over yet.
Next it’s over to Ruochen Wang, who is learning Korean (I am curious why). We hear Advanced Voice Mode generate a Korean phrase, speak it slowly, then quickly.

Again, I get that this is basically a vehicle to show off multimodal capabilities. But anglophone AI researchers still learning foreign languages, in a way that looks remotely like this, makes me feel pretty far from ‘transformative AI’.
Here’s something that would’ve felt very alive:
- Could they invite on someone who doesn’t speak English and have them contribute / participate as much as everyone else? Negligible latency. That, to me, is a watershed moment. All this ‘basic English to basic foreign language, bijective mapping between lexemes’ is not it.
Or (more realistically):
- Can they change language-learning from active to passive? These use cases count on initiative and discipline. Everyone comes up short sometimes. Where’s the ‘self-activating’ voice mode—one that jumps into practice with you at random / set intervals? Proactive immersion?
Or (moreover):
- Could they demonstrate new frontiers in literature, i.e. how GPT-5 might help an English-speaker quickly internalize, parse, & activate a Russian pattern of thought? That would be showstopping.
Some consider it philistine to ignore language-learning just because we have machine translation now. But I think bringing a language to a person who doesn’t speak it is a phenomenal technical challenge. It’s one translators of literature have been facing for decades. How do you capture the space between Russian and English, or Latin and English? This makes me excited—as opposed to something as unscalable and arbitrary as picking one language from many and learning it.
(Tangent) I also think we should probably hack on English as a huge open-source language more. Push it to its limits, bring in the legitimately ‘untranslatable’, and double down on having one Schelling language. I understand we’ve been doing this passively for the past several centuries, but I’ve never seen a serious initiative for the popularization of patterns we’re missing. How do we make it such that you don’t miss out on anything by being solely monoglot? (for any given language?)
Then there are all these bugbear questions about fundamental units of linguistic representation…which I hope to get into in a future post.
I understand that most of the features I discuss above involve ‘wrappers’ on the foundational tech, and that OpenAI’s mission is developing the foundational tech, etc.. I get that it’s basically up to users/developers to flesh out the details here. And good on them for making me think about this, ‘so close yet so far’, etc etc.. I liked this note recently:
it’s funny how many AI skeptics unconsciously anthropomorphize LLMs in their critiques, like their anger is directed more at a naive zoomer intern who can’t infer the context of your ask, rather than a computer program that can work small miracles if you have the patience to learn how it thinks.
no one gets mad at the limitations of their microwave, or even a stats package, the way they get worked up over a machine in a box that four years ago couldn’t do addition and today wins math olympiads. in that anger is an implicit assumption: that it should know better — and of something on the other end that’s far more than a machine, if not quite yet a soul
7
Originally published on Substack