"90/30 ML Reading Group: Retrospective"
90/30 ML Reading Group: Retrospective
This corner of the SF AI scene is wonderful
Jun 24, 2025
7
For seven weeks, I ran an ML reading group in San Francisco. Here are 13 things I learned.
- Cross-context groups can work well
In the first week, I was nervous about how more experienced attendees / people who work in ML full-time would find the group. I wanted to keep it open to all backgrounds, & I was on the newer end. I know it’s hard to have great discussions when participants lack context.
To this end, I set up a ‘no dumb questions’ room and a ‘prior knowledge assumed’ room. This worked great—for the ‘no dumb questions’ room! No one really wanted to join the ‘prior knowledge assumed’ room, and instead some milled awkwardly between the two. Then various experts started drifting into the ‘no dumb questions’ room, delighting in giving explanations and answering newbies’ questions. This was awesome and unexpected! From second week onwards, I gathered everyone together, and this seemed to work better—informed amateurs could ask questions; experienced members could discuss these publicly or volunteer to present.

Going back, I’d rename the latter to something like ‘I read the paper’ room, which might’ve been friendlier.
- Amazing people come out of the woodwork on lu.ma
Initially, this reading group was meant to be for Mox members and +1s; being open to the public was incidental. But I was blown away by the people who found us on lu.ma! Many became dedicated members; some were incredibly generous with their time. Two are now leading the group.
I think this is largely testament to San Francisco’s greatness. But it’s also something I think might replicate. On lu.ma, you can add ‘registration questions’ and ask people for their socials, background, reasons for interest, etc.. This is a very effective filter for assembling people who’ll get on well.
- Picking an ‘old’ reading list was a great decision
I didn’t have to use that filter much, though, because virtually all people who signed up turned out to be genuinely interested (which in turn made them great fits for the group). I used the potentially apocryphal ‘Ilya list’, supposedly given by Ilya Sutskever to John Carmack in ~2020: “If you really learn [these 30 papers], you’ll know 90% of what matters today." (That’s how the club got its name!). These are mostly pre-2020, somewhat off-the-beaten-track, and I think this helped attract a thoughtful crowd.
The other reading list I considered using was Latent Space’s, which I think would’ve had different effects. (The group might progress to these.)
 Latent.SpaceThe 2025 AI Engineer Reading ListDiscussions on X, LinkedIn, YouTube. Also: Meet AI Engineers in person! Applications closing soon for attending and sponsoring AI Engineer Summit NYC, Feb 20-21…Read more9 months ago · 550 likes · 18 comments
Latent.SpaceThe 2025 AI Engineer Reading ListDiscussions on X, LinkedIn, YouTube. Also: Meet AI Engineers in person! Applications closing soon for attending and sponsoring AI Engineer Summit NYC, Feb 20-21…Read more9 months ago · 550 likes · 18 comments- Attendee interest is heavy-tailed
Known to event organizers world-over: half of people who sign up won’t show. I missed that memo ordering pizza in first week.
By contrast, some dedicated members will present every week, or step up to lead the club when you leave the city. <3 It’s not always who you’d expect.
- I’m going to really enjoy studying graph theory
I loved Pointer Networks. I also really liked looking at relational reasoning networks. Speaking of…
- Great analogies work wonders
My compatriot Xi is a gifted explainer. He explained ‘A simple neural network module for relational reasoning’ by way of analogy.

Analogy with washrooms, that is. Imagine living in a student dorm. Think how inefficient it would be if every room were to have its own en-suite! A collective washroom is much cheaper. With that established, Xi continued through the rest of the paper.
Halfway through, Xi refined his analogy. Since the comparison functions have two inputs, what about speed-dating? Imagine if, for any given couple, we had to train an aunty from scratch to determine their compatibility. Now imagine we have one highly trained, specialized individual performing this job. Much more efficient! Much easier to re-use lessons from pair to pair! I don’t think we’ll forget the key concept here.
- Audience participation works wonders
Another great presentation came from Oscar. Oscar recited miscellaneous words (“apple…table…chair…”) for a minute, then had us scribble down / call out as many as we could. The first and last few words were slightly over-represented. This primed us superbly for Lost in the Middle: How Language Models Use Long Contexts.
- OpenAI trained GPT-2 on links liked by Redditors
 I just found this interesting. Creative, effective dataset construction. Redditors punching above their weight.
I just found this interesting. Creative, effective dataset construction. Redditors punching above their weight.
- There are a few different categories of ML paper
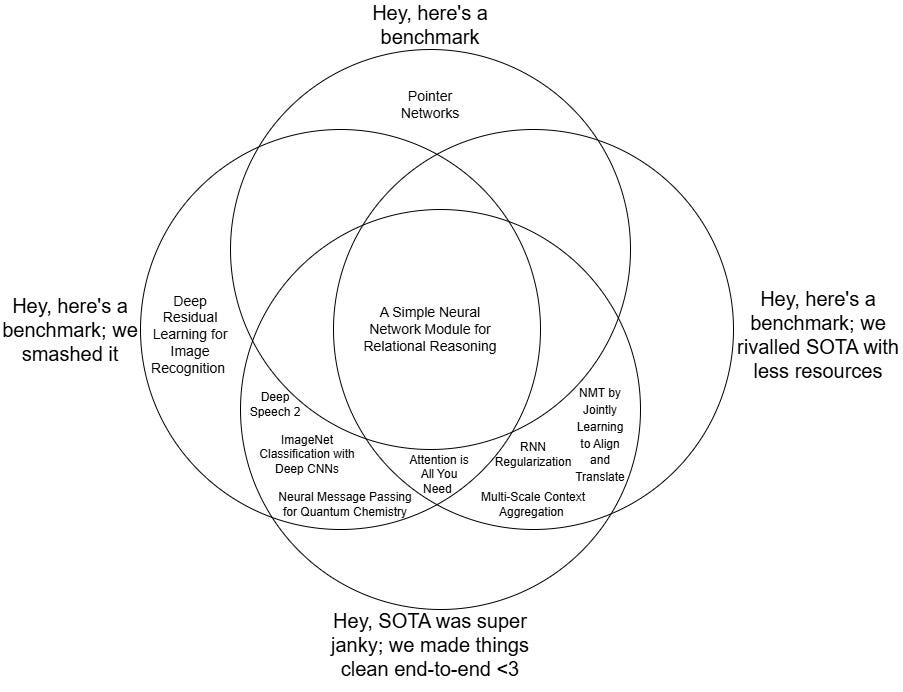 Refinements welcome
Refinements welcome
- Folk wisdom abounds
There are some recurring themes that resonate with a wide range of backgrounds. Here are some that come to mind:
-
‘Simple wins out’
- LSTM+attention is a more sophisticated use of attention (incorporates attention distribution into the context vector), but pointer network performs better (just outputs the most attended-to point)
-
Gains from specialization
 ML echoes Econ sometimes
ML echoes Econ sometimes
- Crowdsourcing is tough but rewarding
Week Five was ‘bring your favorite paper to present’ week. I started calling for proposals from Week 3. In the lead-up, the number of presentations oscillated between too many and too few. Thanks to the general awesomeness of the group, things turned out just right. It was stressful, but I was happiest with how this week turned out! People presented on:
-
Meta-Learning Fast Weight Language Models
-
‘Thinking fast and slow’!
-
The fast layers learn their own low-rank update rule. This is awesome, efficient metacognition.
-
-
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
-
Another example of ‘gains from specialization’.
-
Notably, people were divided over / couldn’t work out if GPT-4 was a Mixture of Experts model for a while. (It is.)
-
Competition for how large people could make their models (how many parameters they could incorporate) heated up in the mid-2010s, leading to amusing titles like this.
-
-
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
- This paper made a real impression on me when it came out in August. Now, I’m struck by how janky the workflow is! I still think it’s a landmark paper in a fast-growing field.
-
Taha’s mathematical wanderings
- Answering the call of non-linearity!
-
Neural Networks, Types, and Functional Programming
- Improving models is like playing with Lego. By stacking computationally cheaper architecture on top of a transformer (which we try to backpropagate through as little as possible), we can make gains: we saw that in "Better & Faster Large Language Models via Multi-Token Prediction" and “Meta-Learning Fast Weight Language Models”. Olah’s blogpost gives intuition for what we’re playing with.
-
Differential Euler: Designing a Neural Network Approximator to Solve the Chaotic Three-Body Problem
- Presented by its author; we were fortunate.
-
This won’t live in recorded history
Besides my Google Drive comments, there won’t be much record of what we discussed. That’s partly why I wanted to write this blogpost. Documentation is one of those ‘important-not-urgent’ things worth solving. I’m excited to see how the new hosts approach this!
- Socratica & I are better apart
Before 90/30 Club, I used to help run weekly sessions of [orchard], a UK Socratica node. I think the Playspace (SF Socratica) hosts put it beautifully when they said:
[…] there eventually reaches a point where an intentionally broad space like Playspace no longer becomes the ideal container to delve deeper in specific interests. Many of us found ourselves slowly gravitating towards smaller, more dedicated spaces for our interests […] In this way, Playspace served as a kind of ‘hub world’ where people discovered both their passions and their people before venturing out to create more focused spaces together.
I loved being in a fully AI/ML-focused group at 90/30 Club. I’d like to contribute to increasingly field-specific spaces as time goes on.
Thanks to Ryo, Max, Oscar, Taha, Bhavesh, Logan, Euan, Yudhister, Antonio, Justin, Anshu, Xi, George, Campbell, Anup, Akhil, Jordan, Greg, Austin, Rachel, & everyone <3
pronotre is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Subscribe
7
Originally published on Substack